Журнальная версия: Ильясов Ф. Н. Типы шкал и анализ распределений в социологии // Мониторинг общественного мнения: экономические и социальные перемены. 2014. №4. С. 24-40. Скачать PDF
Ильясов Фархад Назипович
ТИПЫ ШКАЛ И АНАЛИЗ РАСПРЕДЕЛЕНИЙ В СОЦИОЛОГИИ
Iliassov Farkhad Nazipovich
TYPES OF SCALES AND ANALYSIS OF DISTRIBUTIONS IN SOCIOLOGY
Аннотация. Цель статьи – описать некоторые особенности анализа социологических распределений в соответствии с изложенным ранее пониманием шкал и специфики социологического измерения. Описано соотношение атрибутивных, порядковых и абсолютных шкал с типами социологических распределений. На примере анализа президентских выборов в РФ и Франции 2012 г. показаны возможности сравнительного анализа атрибутивных шкал. Проанализирован феномен распределения ранг-размер. Показано, что атрибутивные шкалы зачастую представляют собой «свёрнутые» порядковые шкалы, а понятие «качественный признак» нередко лишено формального смысла. Теоретически обоснован и описан эксперимент по измерению удовлетворённости местом работы двумя раздельными порядковыми шкалами. Изложено понимание феномена доверия и эксперимент по измерению доверия – недоверия двумя раздельными порядковыми шкалами с использованием новых аналитических походов. Показывается необоснованность использования гипотезы нормального распределения в социологии. Распределения по возрасту проанализированы как особый тип распределений, сформулирована гипотеза, объясняющая типичную форму кривых распределений по возрасту. Вкратце описан феномен распределение величин свойства по временной шкале.
Abstract. The purpose of the article - to describe some features of the sociological analysis of distributions in accordance with the previously stated understanding scales and specificity of the sociological measurement. Described attributive, ordinal and absolute scales with types of sociological distributions. An analysis of the presidential elections in Russia and France, showing the possibility of a comparative analysis of attributive scales. Analyzed the phenomenon of rank-size distribution. It is shown that attributive scales are often rolled ordinal scales, and the notion of "quality characteristic" is often unreasonably. Theoretically-founded and describes an experiment to measure workplace satisfaction twin ordinal scales. Stated understanding of the phenomenon of trust and describes an experiment on the measurement of trust - distrust twin ordinal scales using new analytical campaigns. Showing the invalidity of the use of the hypothesis of normal distribution in sociology. Analyzed as a particular type of distribution by age? formulated a hypothesis that explains the typical shape of the curves similar distributions. Briefly describe the phenomenon distribution units properties in the timeline.
Ключевые слова: социологические шкалы, социологические распределения, ранг-размер, амбивалентность оценок, удовлетворённость местом работы, доверие, нормальное распределение
Keywords: sociological scale sociological distribution, rank-size, ambivalence ratings, workplace satisfaction, trust, a normal distribution
Цель статьи – описать некоторые особенности анализа социологических распределений в соответствии с изложенным ранее пониманием шкал и специфики социологического измерения [Ильясов, 2014].
Типы шкал и распределений
В результате опроса исследователь получает различные типы распределений ответов. Тип используемых в опросе шкал задаёт тип получаемого распределения – атрибутивное, порядковое, абсолютное, временное (см. табл. 1). Об авторском понимании типов шкал см.: [Ильясов, 2014].
Атрибутивное распределение получается в результате выделения респондентов только по наличию одного исследуемого свойства, оно отражает долю респондентов в выборке, обладающих измеряемым свойством, например, женским полом или определённой национальностью.
Порядковое распределение есть распределение респондентов по рангу величины свойства, например, по степени согласия с некоторым утверждением, по даваемым оценкам или по уровню квалификации.
Абсолютное распределение есть распределение респондентов по величине исследуемого свойства – например, распределение респондентов по уровню дохода или по возрасту.
Временные, динамические распределения представляют собой распределение величин свойства по временной шкале (времени измерения) – например изменение во времени рейтинга доверия политику.
Табл. 1. Тип шкал и получаемые распределения
| Наименование шкал и распределений | Характеристика распределений | Примеры |
|---|---|---|
| Атрибутивные | Выделение респондентов по наличию одного исследуемого свойства | Количество респондентов определённого пола, национальности, конфессии или голосующих за определённого кандидата на выборах |
| Порядковые | Распределение респондентов по рангам величины измеряемого свойства | Распределения по степени согласия с некоторым утверждением, по даваемым оценкам |
| Абсолютные | Распределение респондентов по величине измеряемого свойства | Распределение респондентов по уровню дохода, возрасту |
| Временные | Распределение величин измеряемого свойства по временной шкале | Изменение во времени рейтинга доверия политику |
Анализ распределений ответов по атрибутивным шкалам
Один из исследовательских артефактов – это восприятие в качестве единой («номинальной») шкалы совокупности однотипных шкал, измеряющих только наличие одного свойства у респондента. На самом деле здесь речь идёт о совокупности независимых, не связанных друг с другом, атрибутивных шкалах, каждая из которых фиксирует количество респондентов в выборке, обладающих определённым атрибутом (свойством). Подробнее об артефакте номинальной шкалы [Ильясов, 2014]. В качестве фиксируемого отдельного свойства выступают, например: готовность проголосовать за кандидата Иванова, приверженность газировке «Тархун», идентификация себя с татарским этносом, и т.п.
Атрибутивные шкалы отражают структуру выборки – выделяют исследуемые группы, представляют данные для их изучения. Здесь можно выделить два направления изысканий:
а) анализ поведения выделенной группы (т.е. изучение связей с другими индикаторами исследования), либо сравнение поведения нескольких групп, выделенных по одному основанию;
б) анализ соотношения размеров выделенных групп. В данном случае возможны следующие аналитические процедуры:
- Выделение модальной группы.
- Ранжирование групп по числу респондентов.
- Вычисление меры рассеяния респондентов по выделенным группам – среднего квадратического (стандартного) отклонения (s) и коэффициента вариации (Vs).
Анализ соотношения размеров групп, выделенных однотипными, но не идентичными атрибутивными шкалами, возможен при сравнении различных генеральных совокупностей. Рассмотрим для примера распределения избирателей по однотипным атрибутивным шкалам на примере результатов голосования на выборах президента РФ и Франции в 2012 г., – см. табл. 2, рис. 1. Среднее арифметическое значение здесь показывает процент голосов, полученный в среднем одним кандидатом (в данном случае этот показатель не информативен, так как всецело зависит от числа анализируемых атрибутивных шкал). Стандартное (среднее квадратическое) отклонение показывает, на сколько процентов в среднем отклоняется процент голосов, полученных кандидатом, от среднеарифметической величины. Коэффициент вариации есть отношение стандартного отклонения к среднеарифметической, выраженное в процентах, он позволяет более корректно сравнивать разные выборки.
Табл. 2. Результаты голосования на выборах президента РФ (2012 г.) и первого тура президентских выборов во Франции (2012 г.)
| Кандидаты, РФ | % | Ранг | Кандидаты, Франция | % |
|---|---|---|---|---|
| Владимир Путин | 63,60 | 1 | Франсуа Олланд | 28,63 |
| Геннадий Зюганов | 17,18 | 2 | Николя Саркози | 27,18 |
| Михаил Прохоров | 7,98 | 3 | Марин Ле Пен | 17,90 |
| Владимир Жириновский | 6,22 | 4 | Жан-Люк Меланшон | 11,10 |
| Сергей Миронов | 3,85 | 5 | Франсуа Байру | 9,13 |
| – | – | 6 | Ева Жоли | 2,31 |
| – | – | 7 | Николя Дюпон-Эньян | 1,79 |
| – | – | 8 | Филипп Путу | 1,15 |
| – | – | 9 | Натали Арто | 0,56 |
| – | – | 19 | Жак Шеминад | 0,25 |
| Среднее | 20,00 | – | Среднее | 10,00 |
| Стд. отклонение (s) | 25,02 | – | Стд. отклонение | 11,03 |
| Коэффициент вариации (Vs) | 125,1 | – | Коэффициент вариации | 110,3 |
Рис. 1. Распределение голосов избирателей на выборах президента в РФ и Франции (первый тур) в 2012 г.*
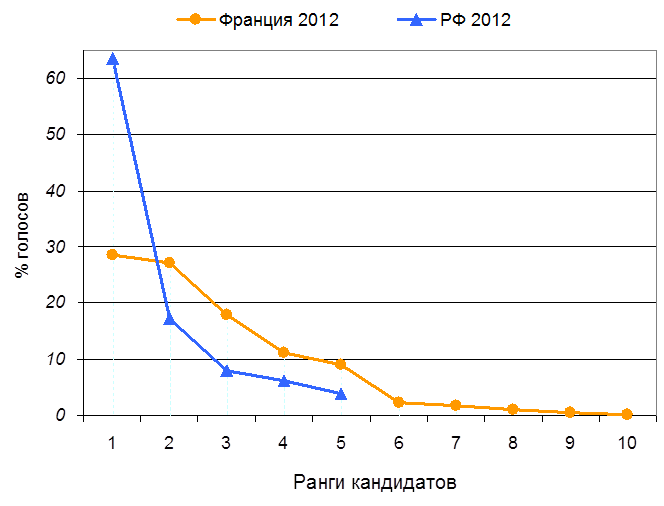
* Соответствие рангов фамилиям кандидатов приведено в табл. 2.
Сравнение величин коэффициента вариации Vs показывают, что в РФ разброс голосов (Vs=125,1%) больше, чем во Франции (Vs=110,3%) – см. табл. 2. Аналогичным образом можно истолковать график, приведённый на рис. 1. Эти данные можно расценивать как свидетельство большей конкурентности выборов во Франции, так как там меньше разница в количестве голосов, полученных разными кандидатами.
Распределения «ранг-размер»
Ранжирование групп по числу респондентов, выделенных атрибутивными шкалами, приводит к идее поиска возможных закономерностей в получаемых ранжированных рядах (распределениях). Американский лингвист Джордж Ципф (George Zipf), анализируя распределения частот слов естественного языка, пришёл к выводу, что эти частоты подчиняются определённой закономерности. Например, первое по частоте (рангу) слово встречается примерно в два раза чаще, чем второе, и в три раза чаще, чем третье, и т.д. Такого рода распределения, когда частота первого по рангу свойства в определённой прогрессии превышает частоту следующих по рангу свойств, называют распределением ранг-размер (либо ранговым распределением). Указанная закономерность получила наименования закона Ципфа (существуют модификации закона с другими названиями), см., например: [Буховец, 2005].
Если распределения строятся путём ранжирования величин групп, то можно ожидать, что в силу простого совпадения, некоторая часть из этих распределений будет соответствовать закону Ципфа, то есть снижение величин групп будет с некоторой степенью погрешности подчиняться той или иной прогрессии. Вопрос в том, отражает ли такое распределение устойчивую, «закономерную» структуру объекта исследования, либо оно для данного класса объектов исследования возникает иногда, лишь в отдельных выборках и не связано с какой-либо социологической закономерностью.
В научной литературе встречается мнение, что распределение голосов избирателей на выборах (всегда) подчиняется закону Ципфа. В частности такой точки зрения придерживается Алексей Буховец [Буховец, 2005: 132], и др. Подобную точку зрения оспаривает, например, Михаил Филиппов [Филиппов, 2008].
Авторы, полагающие, что результаты выборов подчиняются закону Ципфа, не дают содержательного обоснования своей точке зрения. Подчинение частотности слов в языке некоторой статистической закономерности может казаться понятным, так как отражает устойчивую природную структуру языка. Однако распределение голосов избирателей не отражает какой-либо неизменной социальной структуры, наоборот, структура электоральных предпочтений представляет собой динамическую систему, распределение голосов избирателей в общем случае не подчиняется единой статистической закономерности и может иметь любой вид. При этом не исключены отдельные эпизоды, когда распределение голосов избирателей будет иметь характер близкий к распределению ранг-размер.
Прогрессия в общем смысле – это последовательность чисел, полученных по определённому правилу. Поскольку распределение ранг-размер есть распределение, построенное на основе некоторой прогрессии, то можно строить прогрессию на основе отрицательной кратности1 частот распределений по отношению к максимальной частоте, т.е. первому рангу. Такое распределение приведено на рис. 2. Отрицательная кратность рейтингу Владимира Путина показывает во сколько раз процент голосов, полученных отдельными кандидатами, меньше процента голосов, отданных за Путина. Как видно на рис. 2, полученное распределение приближённо описывается (аппроксимируется) прямой линией, то есть допустимо полагать, что данное распределение близко к распрямлению ранг-размер.
Рис. 2. Распределение результатов голосования на выборах президента РФ в 20012 г. построенное на основе отрицательной кратности по отношению к максимальному результату
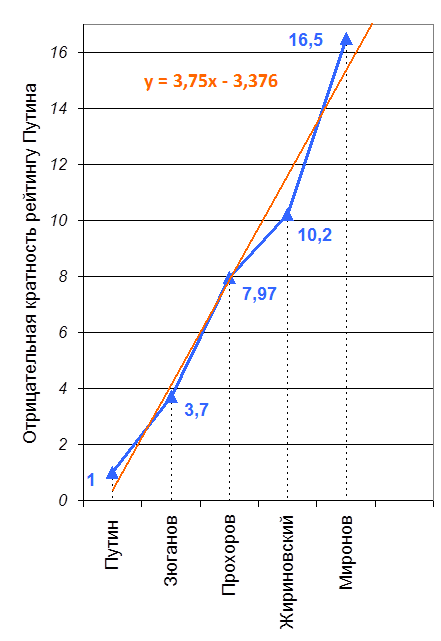
Оранжевая линия отражает линию тренда.
Построенный подобным образом график результатов голосования во Франции по форме имеет вид схожий с гиперболой – см. рис. 3 (линия тренда описана экспоненциальной кривой). Приведённые данные позволяют предположить, что результаты выборов в отдельных случаях могут с некоторой погрешностью описываться различными прогрессиями.
Рис. 3. Распределение результатов голосования на выборах президента Франции в 2012 г. (первый тур) построенное на основе отрицательной кратности по отношению к максимальному результату
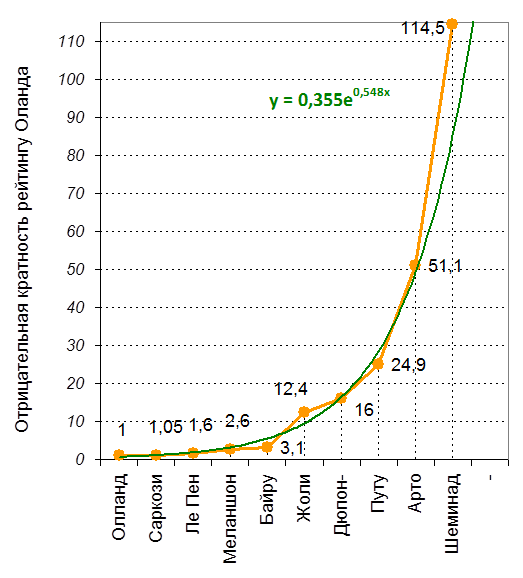
Зелёная линия отражает линию тренда.
Атрибутивные шкалы как «свёрнутые» порядковые шкалы
Атрибутивные («номинальные») шкалы иногда называют «качественными», возможно подразумевая под этим, что фиксируемые ими свойства не могут иметь количественного измерения. Этот тезис, как представляется, не вполне соответствует действительности – «качественный признак» зачастую измерим.
Восприятие группы однотипных атрибутивных шкал как единой «номинальной шкалы» заслоняет собой одно важное обстоятельство – атрибутивные шкалы упрощают реальность до «качественного признака». На самом деле они, как правило, представляют собой «свёрнутую» порядковую шкалу. Например, атрибутивная шкала электорального рейтинга фиксирует частную электоральную установку – количество респондентов, готовых голосовать за определённого кандидата. Однако возможно ещё измерение силы, активности этой готовности. Соответственно, возможно конструирование шкалы, измеряющей активность такой установки. Нередко электоральная установка имеет амбивалентный характер, потому возможно использование двух шкал, измеряющих активности позитивной и негативной электоральных установок по отношению к одному и тому же кандидату.
Атрибутивные шкалы можно подразделить на две группы:
1. субъективные – шкалы групповой самоидентификации, измеряющие пол, конфессию, профессию, этнос и т.д.;
2. объективные, фактографические – отражающие факты наличия у респондента определённого объективного свойства (обладание определённым предметом, совершения некоторого действия и проч.).
Рассмотрим некоторые шкалы групповой самоидентификации. При измерении национальности в социологии и переписях населения обычно фиксируется преимущественная самоидентификация респондента с одним определённым этносом. При этом за пределами измерения остаётся тот факт, что значительная часть респондентов генетически не являются моно-этничными, так как являются детьми (внуками, правнуками) межэтнических браков. Для отражения факта полиэтничной самоидентификации респондента, может измеряться степень его этнической самоидентификации с несколькими этносами (например, русский на 50%, татарин на 25%, еврей на 12,5%, и т.д.).
Самоидентификация респондента с конфессиональной принадлежностью в некоторых опросах измеряется атрибутивными шкалами, фиксирующими наличие определённого свойства – христианин, магометанин, иудей, буддист и т.д. Такая самоидентификация на самом деле может иметь два параметра. «По горизонтали» – причисление себя к определённой конфессии, здесь, как известно, встречается феномен поли-религиозности – одновременное исповедование двух или более религий. «По вертикали» – мера включённости в религию, степень религиозности, которая может измеряться порядковой шкалой, см., например: [Ильясов, 1987]. То есть возможно измерение того: а) на сколько процентов респондент христианин или магометанин, буддист и т.д., б) в какой мере он религиозен.
Измерение пола в социологии осуществляется посредством половой самоидентификации. Значительная часть людей, как известно, ощущают в себе одновременно свойства (черты характера, особенности поведения и т.д.) и мужского, и женского пола. Выраженность этих свойств может представляться в процентах, что и делается в соответствующих психологических тестах. Не говоря о том, что само количество полов по критерию самоидентификации имеет тенденцию к увеличению. В качестве casus vivendi («случая из жизни») можно привести пример с интернет ресурсом Facebook, поместившим в феврале 2014 года в регистрационной анкете для жителей США около 50 вариантов ответа на вопрос о половой самоидентификации.
Мера отнесения респондента к определённой профессии также измеряема: а) «по вертикали» – профессиональной квалификацией, б) «по горизонтали» – степенью обладания знаниями, навыками и умениями смежных или разных профессий.
Подобные обоснования могут быть приведены относительно измерения иных случаев групповой самоидентификации. Таким образом, можно полагать, что значительная часть атрибутивных шкал представляют собой «свёрнутые» порядковые, а возможно и абсолютные шкалы.
Выражение «качественный признак» в данном контексте, как представляется, лишено формального смысла, ибо оно обозначает лишь то, что из некоторых соображений используется «огрублённая» шкала, не измеряющая «количества» – степени выраженности фиксируемого свойства.
Аналогичные соображение могут быть приведены и при анализе дихотомических шкал – они зачастую являются «свёрнутыми» порядковыми, сводимыми к абсолютным. К примеру, ответ на фактографический вопрос может иметь порядковое либо абсолютное измерение. В частности, ответ на вопрос типа: «Имеете ли вы автомобиль?» может не исчерпываться дихотомическим ответом «да» или «нет». Респондент может быть юридическим или фактическим: а) совладельцем, б) со-пользователем, в) со-распорядителем автомобиля (что часто бывает в семьях). При этом его доля может быть измерена точно – по юридически оформленной или подразумеваемой доле, по доли времени реального пользования и распоряжения.
Распределение частоты ответов по делениям порядковых шкал
Порядковые распределения тем или иным образом отражают измерения чувств, оценок. Алла Купрейченко указывает: «Исследовательские данные относительно позитивных и негативных чувств показывают, что они существуют, скорее, как двухполюсные конструкты (М. Бурк с соавт., Д. Ватсон и А. Теллген). По данным этих авторов, позитивная аффективность (например: радость, восторг, любовь, счастье) не антонимична высоконегативной аффективности (страдание, презрение, испуг, ненависть и т.д.)» [Купрейченко, 2008: 98]. Этот существенный момент нередко игнорируется в социологии.
В социологической практике при использовании оценочных шкал часто используется двумерный вопрос-индекс, то есть шкала, в которой одновременно содержатся два вопроса – измеряются и положительные оценки (согласие, одобрение, положительное отношение, удовлетворённость), и отрицательные (несогласие, неодобрение, отрицательное отношение, неудовлетворённость). При этом подспудно подразумевается, что используемая шкала является одномерной, что представляется не вполне корректным, так как подобные оценки являются амбивалентными, двумерными.
Для проверки гипотезы о двухмерности оценки удовлетворённости местом работы автором был проведён эксперимент. В экспериментальном онлайн опросе2 задавалось два вопроса – один только про удовлетворённость местом работы, другой только про неудовлетворённость местом работы. Результаты приведены в табл. 3 и на рис. 4.
Табл. 3. Распределение ответов респондентов на два* вопроса об удовлетворённости местом работы
| Насколько вы удовлетворены своим местом работы? | % | Насколько вы не удовлетворены своим местом работы? | % |
|---|---|---|---|
| Полностью удовлетворён | 9,6 | Крайне не удовлетворён | 12,3 |
| Большей частью удовлетворён | 39,5 | Большей частью не удовлетворён | 22,8 |
| Удовлетворён в малой степени | 29,8 | Не удовлетворён в малой степени | 43,9 |
| Удовлетворённость отсутствует | 16,7 | Неудовлетворённость отсутствует | 14 |
| Затрудняюсь ответить | 4,4 | Затрудняюсь ответить | 7 |
* Результаты опроса принимались серверной программой только в случае, если респондент давал ответы на оба вопроса.
Доля лиц давших амбивалентные ответы, то есть одновременно указавших разную меру и удовлетворённости, и неудовлетворённости своим местом работы, составила 61,5% от числа опрошенных. Этот показатель, как представляется, можно рассматривать как индекс амбивалентности удовлетворённости местом работы.
Рис. 4. Распределение ответов респондентов на два* вопроса: 1) Насколько вы удовлетворены своим местом работы?, 2) Насколько вы не удовлетворены своим местом работы?
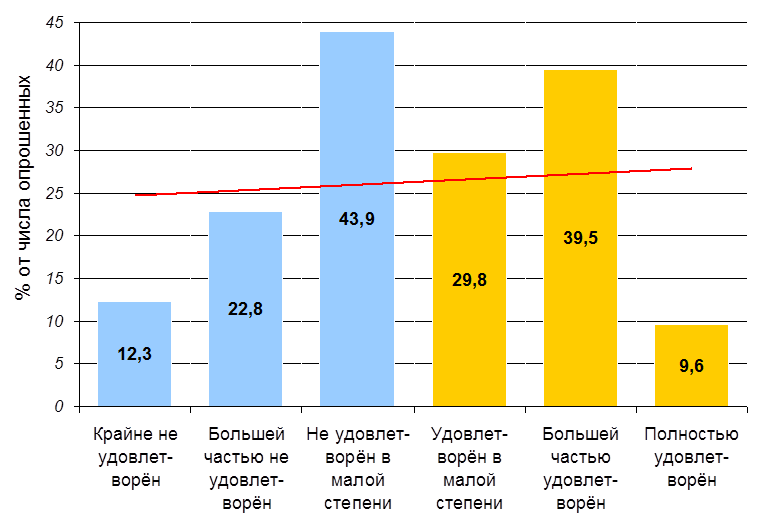
* Результаты опроса принимались серверной программой только в случае, если респондент давал ответы на оба вопроса.
** Красным цветом выделена линия тренда, она показывает небольшое превышение удовлетворённости над неудовлетворённостью местом работы в группе опрошенных.
Если считать по модальным группам, то наиболее типичными ответами для опрошенной группы являются: «Не удовлетворён в малой степени» - 43,9%, «Большей часть удовлетворён» - 39,5%, см. рис 4.
В одной и той же выборке 78,9% респондентов в той или иной мере удовлетворены местом работы и в то же время 79% в той или иной мере не удовлетворены. Приведённое соотношение ответов респондентов показывает, что в данном опросе доля положительных оценок практически равна доле отрицательных. Однако эти цифры не отражают связи количества удовлетворённых и не удовлетворённых с интенсивностью их оценок (которые имеет три градации).
Для отражения интенсивности оценок необходим некий обобщающий показатель удовлетворённости – неудовлетворённости. В качестве такого показателя предлагается использовать индексы удовлетворённости и неудовлетворённости, которые рассчитываются по формуле:
Iумр = (Х3 * 3 + Х2 * 2 + Х1) * 100 / 300;
где: Iумр – индекс удовлетворённости местом работы;
Х3 – доля респондентов полностью удовлетворённых, Х2 – большей частью удовлетворённых, Х1 – удовлетворённых в малой степени;
300 – максимально возможное значение «Х3 * 3» (т.е. в случае, если Х3 = 100%), 100 – число, используемое для приведения полученного результата к процентам.
Iнумр – индекс неудовлетворённости местом работы рассчитывался аналогичным образом.
По результатам обсуждаемого опроса индекс неудовлетворённости местом работы составил 42,1% (напомним, значение этого индекса составит 100%, если абсолютно все опрошенные отметят позицию «крайне не удовлетворён»), а индекс удовлетворённости оказался равен 45,9%, то есть с учётом интенсивности оценок, доля удовлетворённых местом работы в выборке оказалась несколько выше, чем неудовлетворённых. Для более точного измерения указанных индексов необходимо приведение используемых порядковых шкал к абсолютным, как это было показано ранее [Ильясов, 2014].
Измерение доверия – недоверия и его природа
Измерение рейтингов доверия – недоверия является весьма распространённым в практике массовых опросов. Анализ и опыт исследования феномена доверия изложены в психологической и социологической литературе, см. например: [Григоренко 2013; Купрейченко, 2008; Скрипкина, 2000; Экономика и социология доверия, 2004], и др. Теорию вопроса нельзя полагать в достаточной мере разработанной. Обращает на себя внимание и тот факт, что до настоящего времени не сложилось единого понимания феномена доверия – недоверия. Используя понятие доверия, авторы порой подразумевает его различные истолкования. «Несмотря на разнообразие имеющихся теорий, практик и подходов, – указывает Татьяна Скрипкина, – остаётся неясным вопрос о том, что же такое доверие, какова его психологическая сущность, какие функции оно выполняет» [Скрипкина: 2000: 44].
Из изложенного в литературе о феномене доверия можно выделить два существенных момента. Первый – это понимание доверия как установки (хотя не все исследователи разделяют такое понимание). Второй важный аспект – доверие и недоверие не формируют единого континуума, а являются независимыми, самостоятельными феноменами, из чего следует, что они должны измеряться отдельно. Существенным идентифицирующим критерием доверия – недоверия представляются ожидания пользы и ожидания вреда [Купрейченко, 2008].
Проведённые автором в различные годы исследования феномена доверия к политикам, политическим партиям, маркам производителей, товарам, банкам, дали основания полагать, что доверие по своей психологической природе является установкой. Обобщение результатов указанных исследований позволило сформулировать следующее определение, отражающее восприятие респондентами смысла этого слова.
Доверие – это совокупность представлений и настроений субъекта:
а) отражающих его ожидания того, что объект будет реализовывать некоторые функции, способствующие увеличению или сохранению ресурсов субъекта;
б) проявляющихся в готовности субъекта делегировать объекту реализацию этих функций.
Соответственно, недоверие – это ожидания выполнения функций приводящих к уменьшению ресурсов субъекта, приводящие к отказу делегировать объекту выполнение соответствующие функций.
Объектом доверия – недоверия могут выступать отдельные лица, группы, сообщества и структуры любого масштаба вплоть до союза государств, а также предметы, товары, услуги. Различные подходы к пониманию видов и типов доверия и недоверия изложены, например [Купрейченко, 2008: 60-67; Экономика и социология…, 2004: 75-87] и др. Для измерения доверия основополагающим является факт амбивалентности доверия и недоверия. Алла Купрейченко указывает: «В работе Р. Левицки, Д. Мак-Аллистера и Р. Биса отмечается, что доверие и недоверие не являются противоположными концами единого континуума. Это означает, что субъекты способны одновременно доверять и не доверять друг другу. Основаниями подобного подхода эти авторы называют современные социально?психологические исследования отделимости и одновременного существования позитивно?валентных и негативно?валентных аттитюдов (Дж. Кациопо и Г. Бернтсон, Р. Пети, Д. Вегенер и Л. Фабригар)» [Купрейченко, 2008: 98].
Для эмпирического исследования феномена доверия – недоверия автором был проведён экспериментальный онлайн опрос 3, в ходе которого задавались два вопроса, один о степени доверия, другой о степени недоверия политику Владимиру Жириновскому. Результаты опроса приведены на рис. 5 и табл. 4. Выборка не претендует на репрезентативность, задача опроса лишь показать аналитические возможности предлагаемого подхода.
Рис. 5. Распределение ответов на два* вопроса: 1) Насколько вы доверяете Владимиру Жириновскому как политику?, 2) Насколько вы не доверяете Владимиру Жириновскому как политику?
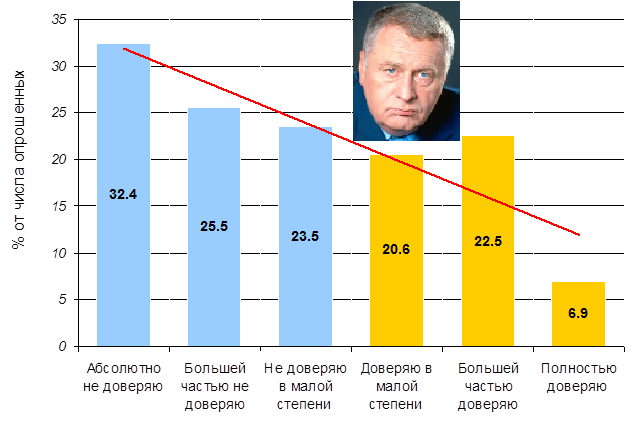
* Результаты опроса принимались серверной программой только в том случае, если респондент давал ответы на оба вопроса.
**Красным цветом выделена линия тренда.
Данные, приведённые на рис. 5 показывают, что распределение ответов респондентов по степени доверия Жириновскому имеет выраженный отрицательный тренд. 81,4% респондентов в той или иной мере не доверяют Жириновскому и в то же время 50,0% в той или степени доверяют ему, при этом полностью доверяют 6,9%.
Табл. 4. Таблица сопряжённости ответов на два вопроса: 1) Насколько вы доверяете Владимиру Жириновскому как политику?, 2) Насколько вы не доверяете Владимиру Жириновскому как политику?
| Степень доверия | Степень недоверия | |||
|---|---|---|---|---|
| Абсолютно не доверяю | Большей частью не доверяю | Не доверяю в малой степени | Недоверие отсутствует | |
| Полностью доверяю | – | – | – | 6,9 |
| Большей частью доверяю | – | – | 18,6 | 2,9 |
| Доверяю в малой степени | 1,0 | 13,7 | 4,9 | – |
| Доверие отсутствует | 31,4 | 10,8 | – | – |
Цветом выделены «амбивалентные» ячейки.
Индекс амбивалентности доверия Жириновскому равен 37,2% (доля респондентов, ответы которых находятся в закрашенных ячейках табл. 4). То есть 37,2% опрошенных респондентов в некоторой мере доверяют и одновременно в некоторой мере не доверяют Жириновскому4 . С одной стороны индекс амбивалентности указывает на меру неустойчивости рейтинга, с другой – на потенциал его укрепления, так как лица с амбивалентным отношением с большей вероятностью могут склониться к однозначному положительному или отрицательному отношению, нежели лица с уже существующим однозначным отношением.
Проведённый эксперимент даёт основания полагать, что, в случае необходимости более точного измерения, рейтинги доверия и недоверия должны измеряться разными порядковыми шкалами, приведёнными к абсолютным.
О гипотезе нормального распределения в социологии
Идею соотношения социологических распределений (шкал, выборок, коэффициентов корреляции) с нормальным распределением можно полагать довольно популярной. Однако этот формально-математический подход не имеет содержательного обоснования в социологии. Ситуация выглядит не вполне прояснённой, в частности не всегда уточняется распределение по каким шкалам может подчиняться закону Гаусса. Распределения по атрибутивным шкалам не могут рассматриваться на предмет соответствия нормальному распределению, так как это независимые шкалы и у них не может быть среднего значения и, соответственно, отклонений от него. Порядковые шкалы также не имеют корректного среднего значения, потому также не могут соотноситься с нормальным распределением.
Анализ распределений респондентов по величине свойства, то есть по делениям абсолютных шкал, с точки зрения их соответствия нормальному закону, на первый взгляд выглядит более обоснованным. Однако среди распределений по абсолютным шкалам не наблюдается типов распределений, соответствующих нормальному. Распределения респондентов по зарплате, доходам, распределения брачующихся и мигрантов по возрасту, и другие подобные распределения имеют правоскошенный характер.
Не удалось найти аргументов, обосновывающих гипотезу о том, почему определённый вид социологического распределения должен (может) подчиняться нормальному распределению. «Во многих случаях, – указывает Александр Крыштановский, – предположение о нормальности обосновать довольно трудно, а подчас можно точно сказать, что распределение резко отличается от нормального» [Крыштановский, 2006: 110]. Александр Орлов делает более широкий вывод: «Как показали многочисленные исследования, почти все распределения реальных данных не принадлежат ни одному из известных параметрических семейств» [Орлов, 2006], см. также [Орлов, 1991].
Ряд авторов отмечают, что нормальное распределение «встречается редко» [Веллеман, Уилкинсон, 2011: 188; Давыдов, 1995: 113; и др.]. Однако приведённая «мягкая» формулировка ни о чём не говорит, а, возможно, лишь отражают инерцию авторитета этого догмата в социологии. Понятно, что какие-то из эмпирических распределений могут иметь вид близкий к нормальному, но это может происходить не в силу закономерности, а вследствие вариативности распределений, то есть «по совпадению». Таким образом, можно предположить, что идея нормального распределения в социологии является необоснованной.
Ряд методов измерения и анализа данных в социологии зиждутся на гипотезе нормального распределения. Поскольку сама гипотеза «нормальности» не находит обоснования и подтверждения, то и методы на ней основанные могут быть недостаточно достоверными.
О возможных различиях в детерминации поведения разных возрастных групп
Распределения по возрасту респондентов, реализующих определённые виды поведение, можно рассматривать как специфическую группу распределений. Известны «демографические» распределения по возрасту респондентов осуществляющих такие виды поведения как миграция, вступление в брак, рождение детей. Они имеют схожий вид – это одномодальные правоскошенные распределения. Значительная часть распределений по возрасту респондентов, реализующих покупательское поведение (автомобили, гаджеты, одежда, турпутёвки, жевательная резинка, газировки и т.д.), также нередко имеет одномодальный правоскошенный характер. Андрей Давыдов придерживается точки зрения, что подобное происходит «из-за неоднородности выборки, в результате чего анализируемое распределение является “смесью” различных распределений» [Давыдов, 1995: 113].
Можно полагать, что в правоскошенных распределениях до достижения модального возраста доминирует одна группа детерминирующих факторов, а затем с увеличением возраста доминирующие факторы меняются. Может быть и такая ситуация, когда одна и та же совокупность детерминирующих факторов с различной силой влияет на разные возрастные группы. Например, по мере приближения к модальному возрасту влияние одних и тех же детерминирующих факторов усиливается, а после модального возраста – снижается. Следовательно, можно полагать, что, в случае подобных одномодальных правоскошенных распределений, исследователь имеет дело не с одним, а, как минимум, с двумя видами распределений. В таком случае должна анализироваться не вся (единая) кривая распределения, включающая все возрастные группы, а отдельные её фрагменты.
На рис. 6 приведено распределение по возрасту посетителей вводного семинара5 , посвящённого работе на рынке Форекс (Forex – валютная биржа). Как видно из графика, модальным возрастом является 23 года (средний возраст респондентов составил около 31 года, стандартное отклонение ±10,7 лет). Анализ «списка мотивов» участия в валютных торгах не выявил прямой связи мотивов с возрастом. Поскольку структура мотивов существенно не различается по возрастным группам, можно предположить, что влияет не различие в списках мотивов, а различия в силе воздействия одних и тех факторов. С 15 до 23 лет факторы, детерминирующие участия в торгах, увеличивают своё влияние на респондентов, а после 23 лет их влияние начинает снижаться.
Рис. 6. Распределение по возрасту посетителей вводного семинара, посвящённого работе на рынке Форекс (валютной бирже)*
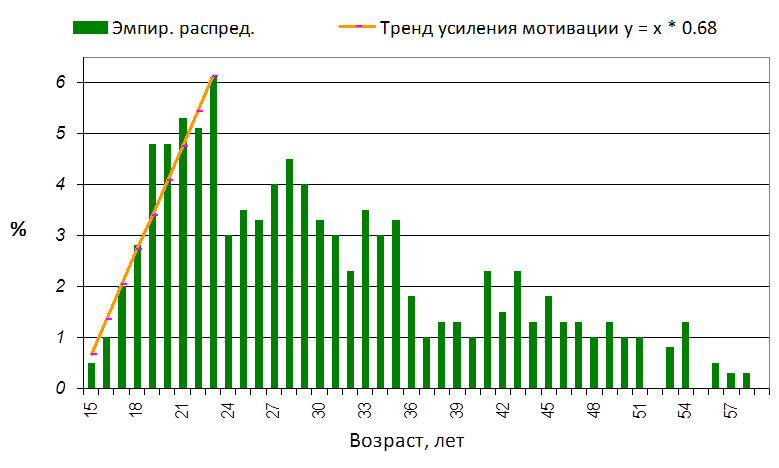
* В формуле тренда усиления мотивации величина «x» это номер возрастной группы (например, для возраста 16 лет x=2).
Не ясно, можно при анализе подобных правоскошенных распределений найти закономерности, связанные с отклонением от модального значения, а не от среднего. Феномен модальной величины привлекает внимание исследователей, см., например: [Чураков, 1999], однако не удалось найти попыток выявления закономерностей распределения построенных на основе модальной величины.
Распределение величин свойства по временной шкале
Временные (динамические) ряды есть распределения величин определённого свойства по шкале астрономического (календарного) времени. Пожалуй, самые популярные из них – это биржевые и валютные котировки, они активно измеряются, исследуются и используются ежеминутно по всей планете. В демографии это изменение во времени различных демографических показателей – рождаемости, смертности и т.д. В социологии измеряется динамика различных рейтингов, динамика изменений состояний массового сознания и массовых настроений («общественного мнения») по тем или иным показателям.
Динамические ряды, в зависимости от характера временного параметра, подразделятся на моментные (на определённую дату) и интервальные (за определённый период). В социологии, как правило, анализируются моментные ряды, то есть изменения значений определённого показателя на моменты (даты) проведения опросов. Использование методов анализа временных рядов в социологии приведено, например, в статье Александра Крыштановского [Крыштановский, 2000].
Временные ряды, как представляется, не корректно соотносить с законами Гаусса или Ципфа. Указанные законы отражают распределение объектов по шкале, отражающей величины измеряемого свойства (например, распределение респондентов по размеру зарплаты), а временные ряды есть распределение величин измеряемого свойства по шкале времени (например, изменение рейтинга доверия по месяцам), то есть это разные по своей природе явления. Хотя проблема соотношения нормального распределения с временными рядами обсуждается, см., например, книгу биржевого трейдера Нассима Талеба (Taleb, Nassim) [Талеб, 2009].
Во временном анализе различаются термины «тенденция» и «тренд». Некое долговременное повышение (понижение) значения показателя, с возможными временными спадами (подъёмами), называют тенденций. А временные спады (подъёмы) в нескольких рядом стоящих моментах, называют трендами. Понятно, что в отдельных случаях тренд может стать тенденцией.
В исследовании временных рядов выделяют фундаментальный и технический анализ. Содержанием фундаментального анализа является выявления влияния «фундаментальных» факторов на динамику измеряемых показателей. Например, в электоральных исследованиях выявляется как те или иные политические и экономические события, публикации, действия политиков и т.п., влияют на рейтинг определённого политика. Зачастую сбор информации в этом случае осуществляется методом фокус-групп.
В случае технического анализа предметом рассмотрения является исключительно характер кривой временного ряда. Популярные инструменты анализа: средняя арифметическая – её разновидность скользящая средняя, отклонения от средних, характер графического рисунка кривой. В социологии технический анализ не популярен.
ЛИТЕРАТУРА
Буховец А. Г. Системный подход и ранговые распределения в задачах классификации // Вестник Воронежского ГУ. Серия: Экономика и управление. 2005. №1. С. 130-142.
Веллеман П. Ф., Уилкинсон Л. Типологии номинальных, ординальных, интервальных и относительных шкал вводят в заблуждение // Социология: Методология, методы, математическое моделирование. 2011. №33. С. 166-193.
Григоренко Б. Ю. Доверие как предмет социологического анализа: социокультурный аспект // Знание. Понимание. Умение. 2013. №1. С. 254-259.
Давыдов А. А. Анализ одномерных частотных распределений в социологии: эволюция подходов // Социологические исследования. 1995. №5. С. 113-116.
Ильясов Ф. Н. Религиозное сознание и поведение // Социологические исследования. 1987. №3. С. 50-55.
Ильясов Ф. Н. Шкалы и специфика социологического измерения // Мониторинг общественного мнения: эконом. и социал. перемены. 2014. №1. С. 3-16.
Крыштановский А. О. Методы анализа временных рядов // Мониторинг общественного мнения: Экономические и социальные перемены. 2000. №2. С. 44-51.
Крыштановский А. О. Анализ социологических данных с помощью пакета SPSS. М.: Издательский дом ГУ ВШЭ. 2006.
Купрейченко А. Б. Психология доверия и недоверия. М.: Институт психологи РАН. 2008.
Орлов А. И. Часто ли распределение результатов наблюдений является нормальным? // Заводская лаборатория. 1991. № 7. С. 64-66.
Орлов А. И. Прикладная статистика. Учебник. М.: Экзамен, 2006.
Скрипкина Т. П. Психология доверия. М.: ИЦ «Академия». 2000.
Талеб Н. Н. Кривая нормального распределения, великий интеллектуальный обман // Талеб Н. Н. Чёрный лебедь. Под знаком непредсказуемости. М.: Колибри, 2009. С. 366-401.
Филиппов М. Г. Воображая фальсификации: споры о волеизъявлении 1993 года // Неприкосновенный запас. 2008. №5.
Чураков А. Н. О специфике модальных групп в частотных распределениях // Социология: 4М. 1999. №11. С. 178-196.
Экономика и социология доверия. Под ред. Веселова Ю. В. СПб: Социологическое общество им. Ковалевского М. М. 2004.
СНОСКИ
1 Кратность показывает, во сколько крат (во сколько раз) одна величина больше другой. Отрицательная кратность показывает во сколько раз одна величина меньше другой.
2 Онлайн опрос проводился с использованием онлайн сервиса Google Docs c 09.01 по 28.01 2013 г. Просьба принять участие в опросе, со ссылкой на онлайн анкету, размещалась на сайте психологических тестов, в опросе могли принять участие все желающие. Опрос предварялся обращением: «Просьба ответить на два вопроса, один о степени вашей удовлетворённости местом работы, другой – о степени не удовлетворённости местом работы». N=114. Опрос носил характер эксперимента, целью которого было проверить гипотезу о двухмерности оценки удовлетворённости местом работы, размер и тип выборки представляются адекватными задаче опроса.
3 Онлайн опрос проводился с использованием онлайн сервиса Google Docs в феврале-марте 2014 г. N=102. Просьба принять участие в опросе, со ссылкой на онлайн анкету, размещалась на сайте психологических тестов, в опросе могли принять участие все желающие. Опрос предварялся обращением: «Просьба ответить на два вопроса – один о степени вашего доверия политику Владимиру Жириновскому, другой о степени вашего недоверия ему».
4 В практике массовых опросов индекс доверия политику может рассчитываться как разница между рейтингом доверия и рейтингом недоверия. При этом для измерения подобных рейтингов используются два вопроса с одним (максимальным) делением шкалы.
5 Опрос проведён в форме аудиторного анкетирования в 2005 г. в нескольких городах РФ, n=399. Использовалась квотная выборка, в качестве квот выступали группы участников семинаров. Генеральная совокупность – посетители вводных семинаров определённого вида в городах их постоянного проведения.